- Latest news▼
-
19:41, April 25 Children’s Hospital Los Angeles and International Center of Professional Development Allergy/Immunology Conference

-
17:31, April 25 JAMA: patient grew long, curly eyelashes because of chemotherapy
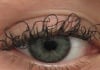
-
11:08, April 25 Mpox epidemic declared in Republic of the Congo

-
08:31, April 25 OU: quitting smoking 4 times more likely to cure laryngeal cancer

-
01:20, April 25 Paralyzed man in China writes hieroglyphs using neural implants placed in his brain

-
15:11, April 24 Zombie deer disease possibly linked to hunters’ deaths

-
12:27, April 23 Appetite: Scientists found out the secret to the appeal of large portions of fast food

-
10:33, April 23 Scientists test new approach to fighting viruses

-
08:38, April 23 Ketamine may help with postpartum depression

-
22:12, April 22 Unhealthy amount of sugar found in baby food products of a well-known brand

-
19:41, April 22 Air pollution puts health of more than 1.6 billion workers globally at risk

-
17:25, April 22 Scientists found baked goods and lack of sleep to be more dangerous than alcohol

-
16:02, April 22 342 cases of measles recorded in Armenia so far in 2024
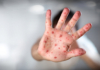
-
15:29, April 22 BrainStimulation: electrical brain stimulation alleviates anxiety and depression in the elderly

-
08:27, April 22 Cognitively stimulating jobs in midlife could lower dementia risk in old age, study finds

All materials
500,000 Britons’ Genomes Will Be Public by 2020, Transforming Drug Research

In an effort to vault genetics into a new era of big data, six drug companies say they will decode the genes of half a million Brits and then make the data public—all by 2020.
As MIT Technology Review reports, the plan will turn the UK Biobank, the source of the DNA samples, into the world’s single biggest concentration of genetic and health data anywhere, giving scientists and drug companies a powerful tool for understanding diseases.
The UK Biobank is already a treasure trove: a public database containing carefully assembled medical records, test results, and even psychological assessments the country has collected from 500,000 volunteers.
Its first big release of data last July—anonymized to protect people’s identities—electrified scientists. With a click of a mouse, they can inspect the genetic basis of everything from diabetes to TV-watching habits.
But the genetic data it contains are limited. Now the sequencing consortium plans to decode all 20,000 or so genes of each volunteer. Such “exome” sequencing falls short of decoding the complete genome, but it captures the parts most important to drug makers—the genetic sequences that code for proteins, the building blocks of life and, when they go awry, the cause of most health problems.
Adding those gene sequences would “increase [the Biobank’s] value 100 times for drug development, and 10 to 100 times for biology,” says Sek Kathiresan, who studies the genetics of heart disease at the Broad Institute in Cambridge, Massachusetts.
The expanded database will, for instance, make it much easier to locate rare genetic mutants whose bodies suggest ideas for new drugs.
Regeneron Pharmaceuticals, the company leading the sequencing consortium, based an anti-heart-attack drug, Praluent, on the 14-year-old chance discovery that certain unusual people who lack a working version of one gene, PCSK9, have incredibly low cholesterol.
That kind of serendipity is being made commonplace by methods that automatically scour data on hundreds of thousands of people. “It takes me and my browser 30 seconds to rediscover PCSK9,” says Regeneron CSO George D. Yancopoulos. “And I think there are thousands of those in the genome.”
The gene decoding effort will occur at Regeneron’s sequencing facility in Tarrytown, New York. Regeneron will be joined by five other drug firms—AbbVie, Alnylam, AstraZeneca, Biogen, and Pfizer—that will each contribute $10 million for the effort. The companies will have private access to the newly created data for 12 months, but then it will become public.
“There is so much information here, there is no one company that can take advantage of all of it,” says Yancopoulos. “We think of this as adding accelerant to science.”
The joint project is not only big news for biomedical science, however. It also widens an already yawning gap between Britain and the U.S., whose own large population study is far behind. According to the National Institutes of Health, the million-person “AllofUs” study has recruited 10,000 people but has not yet sequenced anyone’s DNA.
A spokesperson for the NIH said the $4.3 billion program is “on target” with its goals and plans a national launch this spring.
Yancopoulos calls the slow start by the U.S. “a national embarrassment.” The U.K. data trove is set to dominate “for the foreseeable future, the next five to 10 years,” he says. “It’s going to be the best resource. It’s the first place people will go.”
Follow NEWS.am Medicine on Facebook and Twitter

- Video



- Event calendar
- Children’s Hospital Los Angeles and International Center of Professional Development Allergy/Immunology Conference
- First Armenian-German Conference entitled “Heart Failure Spring School”
- Allogeneic bone marrow transplant in case of hematological malignancy performed in Armenia for first time
All materials
- Archive
- Most read
month
week
day
- JAMA Oncology: Urine test can help rule out high-grade prostate cancer with almost 100% accuracy, study shows 1298
- Scientists grow human mini-lungs in lab 1175
- Next pandemic likely to be triggered by flu - scientists 947
- Scientists found baked goods and lack of sleep to be more dangerous than alcohol 930
- 342 cases of measles recorded in Armenia so far in 2024 883
- Scientists develop new method to safely stimulate immune cells to fight cancer 785
- Cognitively stimulating jobs in midlife could lower dementia risk in old age, study finds 781
- Blood test can determine who is at risk of developing multiple sclerosis - scientists 781
- BrainStimulation: electrical brain stimulation alleviates anxiety and depression in the elderly 721
- Ketamine may help with postpartum depression 667
- Unhealthy amount of sugar found in baby food products of a well-known brand 662
- Appetite: Scientists found out the secret to the appeal of large portions of fast food 657
- Air pollution puts health of more than 1.6 billion workers globally at risk 656
- Scientists test new approach to fighting viruses 641
- Zombie deer disease possibly linked to hunters’ deaths 551
- Find us on Facebook
- Poll